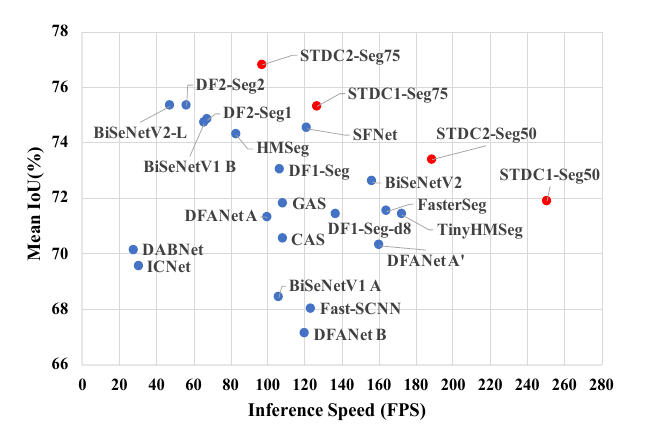
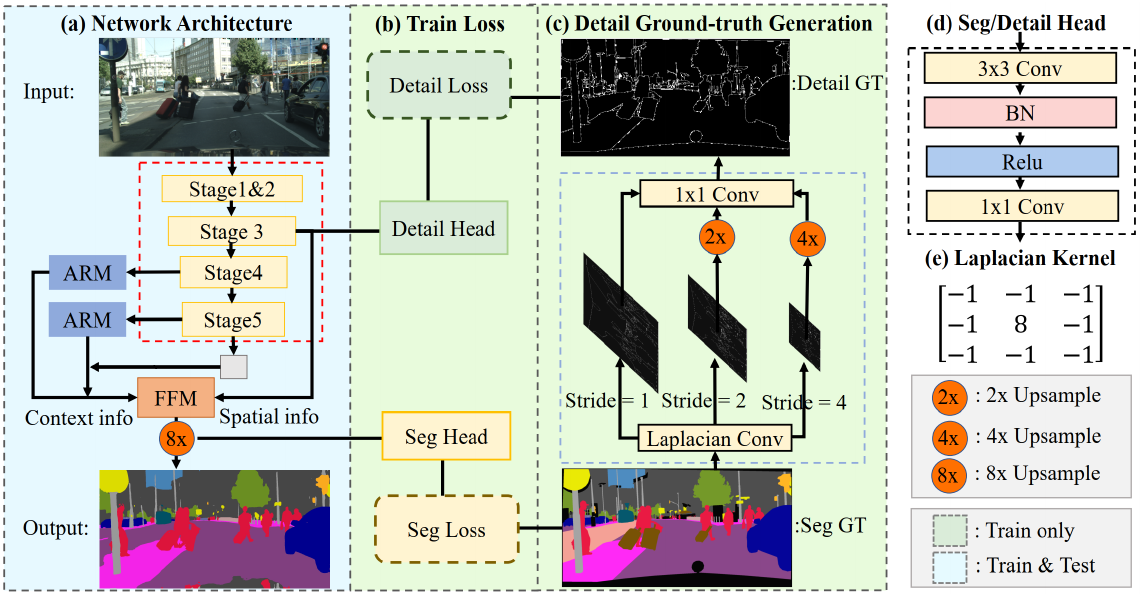
这是一篇讲各种各样解码器的论文。原论文(The Devil is in the Decoder: Classification, Regression and GANs)。
由于“解码器(decoder,有些时候也被称为feature extractor)”的概念与像素级的分类、回归等问题多多少少都有瓜葛。以下是decoder被应用于像素级的任务:
- 分类:语义分割、边缘检测。
- 回归:人体关键点检测、深度预测、着色、超分辨。
- 合成:利用生成对抗网络生成图像等。
所以decoder是稠密预测(Dence prediction,像素级别的很多问题都可以叫做稠密的)问题的关键。
Abstract(摘要)
Image semantic segmentation is more and more being of interest for computer vision and machine learning researchers. Many applications on the rise need accurate and efficient segmentation mechanisms: autonomous driving, indoor navigation, and even virtual or augmented reality systems to name a few. This demand coincides with the rise of deep learning approaches in almost every field or application target related to computer vision, including semantic segmentation or scene understanding. This paper provides a review on deep learning methods for semantic segmentation applied to various application areas. Firstly, we describe the terminology of this field as well as mandatory background concepts. Next, the main datasets and challenges are exposed to help researchers decide which are the ones that best suit their needs and their targets. Then, existing methods are reviewed, highlighting their contributions and their significance in the field. Finally, quantitative results are given for the described methods and the datasets in which they were evaluated, following up with a discussion of the results. At last, we point out a set of promising future works and draw our own conclusions about the state of the art of semantic segmentation using deep learning techniques.
我看了这篇综述受益匪浅,如果有时间的话请阅读原作。本文只是对原作阅读的粗浅笔记。