Xinlong Wang, Tao Kong, Chunhua Shen, Yuning Jiang, Lei Li
We present a new, embarrassingly simple approach to instance segmentation in images. Compared to many other dense prediction tasks, e.g., semantic segmentation, it is the arbitrary number of instances that have made instance segmentation much more challenging. In order to predict a mask for each instance, mainstream approaches either follow the 'detect-thensegment' strategy as used by Mask R-CNN, or predict category masks first then use clustering techniques to group pixels into individual instances. We view the task of instance segmentation from a completely new perspective by introducing the notion of "instance categories", which assigns categories to each pixel within an instance according to the instance's location and size, thus nicely converting instance mask segmentation into a classification-solvable problem. Now instance segmentation is decomposed into two classification tasks. We demonstrate a much simpler and flexible instance segmentation framework with strong performance, achieving on par accuracy with Mask R-CNN and outperforming recent singleshot instance segmenters in accuracy. We hope that this very simple and strong framework can serve as a baseline for many instance-level recognition tasks besides instance segmentation.
实例分割相比于语义分割,不仅需要预测出每一个像素点的语义类别,还要判断出该像素点属于哪一个实例。以往二阶段的方法主要是:
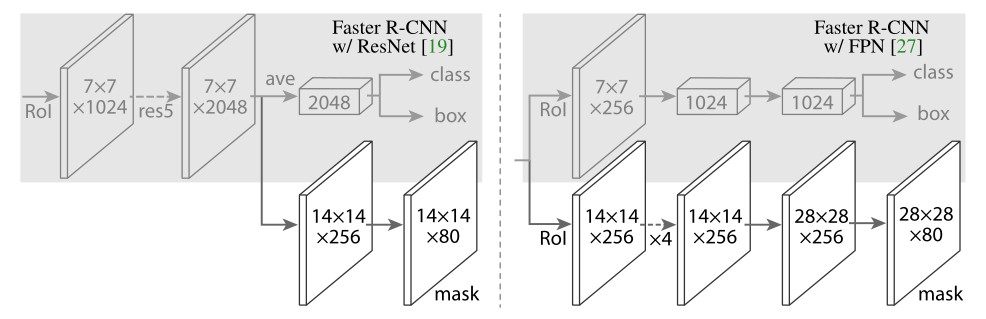
- 先检测后分割:例如Mask R-CNN ,先用检测的方法到得每一个实例,然后对该实例进行语义分割,分割得到的像素都属于此实例。
- 先分割后分类:先采用语义分割的方法对整个图的所有像素点做语义类别的预测,然后学习一个嵌入向量,使用聚类方法拉近属于同一实例的像素点,使它们属于同一类(同个实体)。
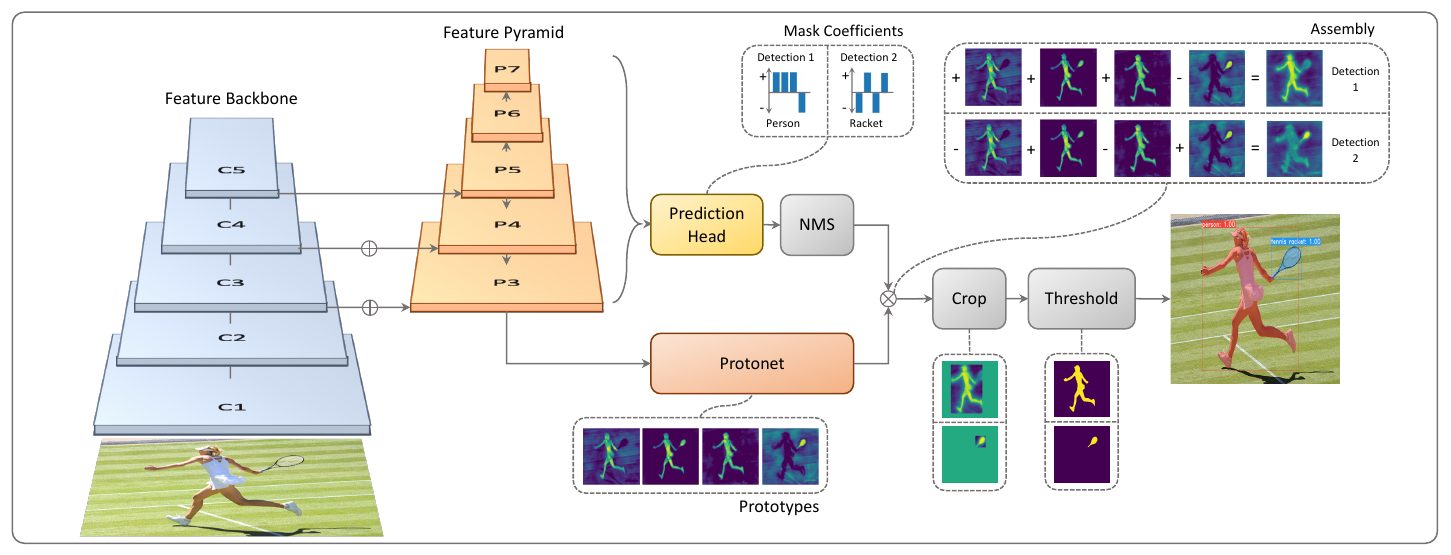
单阶段方法(Single Stage Instance Segmentation)方面的工作受到单阶段目标检测的影响大体上也分为两类:一种是受one-stage, anchot-based检测模型如YOLO,RetinaNet启发,代表作有YOLACT和SOLO;一种是受anchor-free检测模型如 FCOS 启发,代表作有PolarMask和AdaptIS。上述这些实例分割的方法都不那么直接,也不那么简单。SOLO的出发点就是做更简单、更直接的实例分割。
基于对MSCOCO数据集的统计,作者提出,验证子集中总共有36780个对象,其中98.3%的对象对的中心距离大于30个像素。至于其余的1.7%的对象对,其中40.5%的大小比率大于1.5倍。在这里,我们不考虑像X形两个物体这样的少数情况。总之,在大多数情况下,图像中的两个实例要么具有不同的中心位置,要么具有不同的对象大小。
于是作者提出通过物体在图片中的位置和形状来进行实例的区分。同一张图片中,位置和形状完全相同,就是同一个实例,由于形状有很多方面,文章中朴素地使用尺寸描述形状。
该方法与 Mask R-CNN 实现了同等准确度,并且在准确度上优于最近的单次实例分割器。