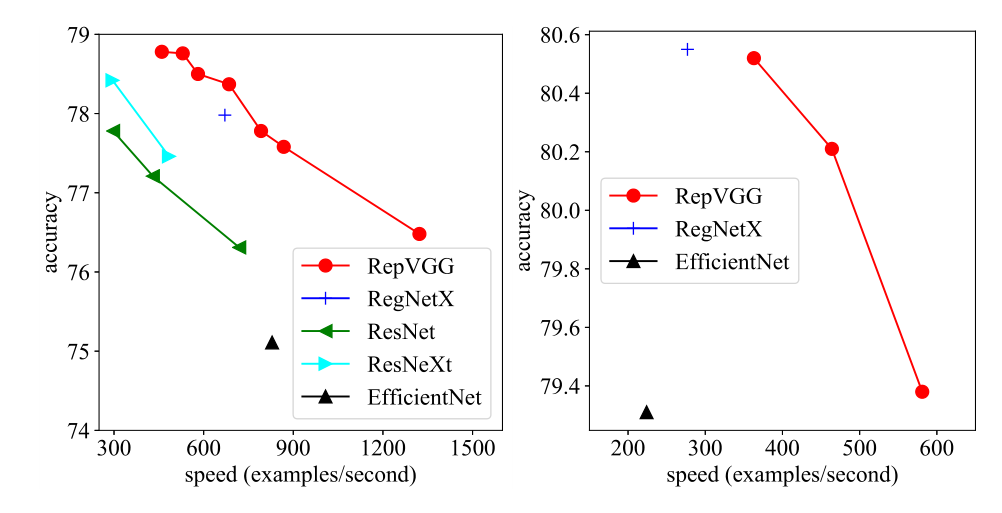
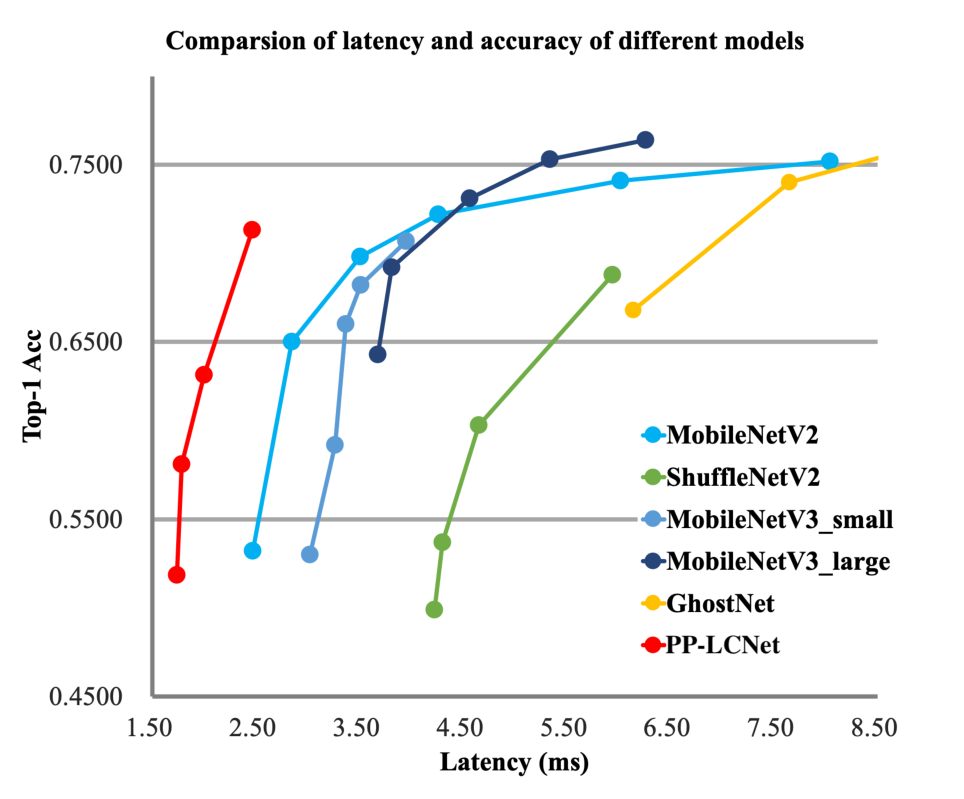
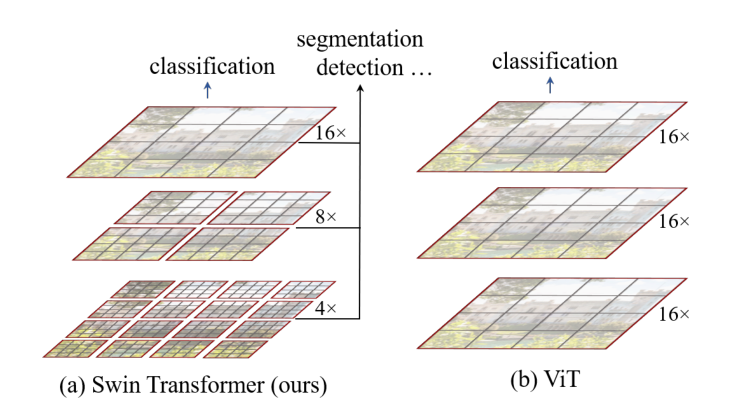
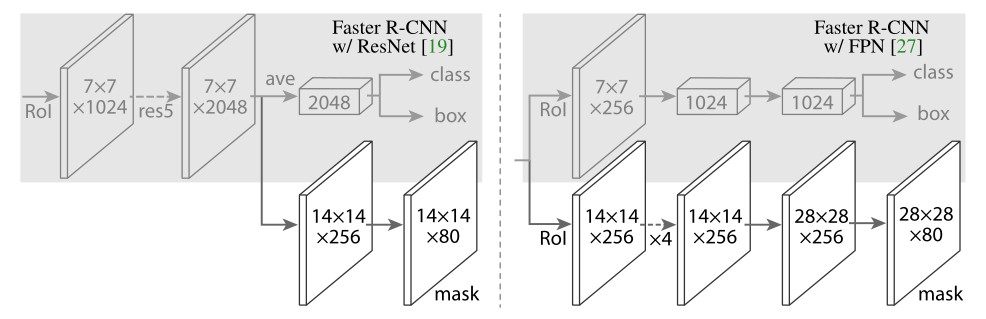
提出十字交叉注意力模块,使用循环稀疏连接代替密集连接,实现性能SOTA
论文名称:CCNet: Criss-Cross Attention for Semantic Segmentation
作者:Zilong Huang,Xinggang Wang Yun,chao Wei,Lichao Huang,Wenyu Liu,Thomas S. Huang
摘要
上下文信息在视觉理解问题中至关重要,譬如语义分割和目标检测;
本文提出了一种十字交叉的网络(Criss-Cross Net)以非常高效的方式获取完整的图像上下文信息:
- 对每个像素使用一个十字注意力模块聚集其路径上所有像素的上下文信息;
- 通过循环操作,每个像素最终都可以捕获完整的图像相关性;
- 提出了一种类别一致性损失来增强模块的表现。
CCNet具有一下优势:
- 显存友好:相较于Non-Local减少显存占用11倍
- 计算高效:循环十字注意力减少Non-Local约85%的计算量
- SOTA
- Achieve the mIoU scores of 81.9%, 45.76% and 55.47% on the Cityscapes test set, the ADE20K validation set and the LIP validation set respectively